Pour mes besoins, j’ai créé un programme qui sert à faire des sauvegardes de fichiers et de bases de données MySQL. Ces sauvegardes sont stockées en local et peuvent être archivées sur Amazon S3 ainsi que sur Amazon Glacier.
Ce programme s’appelle Arkiv et son code source est disponible sur GitHub. Il est placé sous une licence libre très permissive.
Pourquoi avoir développé ce logiciel ?
J’utilisais depuis longtemps le programme Backup-Manager, qui me permettait de sauvegarder mes fichiers et mes bases de données en local et sur un serveur FTP, puis sur Amazon S3. Ce programme est très pratique ; il existe depuis plus de 10 ans (il me semble que je l’utilise depuis tout ce temps), il offre pas mal d’options de configuration, et il est disponible dans les paquets Ubuntu.
Mais avec le temps, mes besoins ont évolué, et certaines limites sont apparues : Il ne permet pas de faire plus d’une sauvegarde par jour, ne supporte pas tous les datacenters Amazon (les plus récents ne sont pas compatibles avec les anciennes versions de l’API), ne permet pas d’archiver sur Amazon Glacier et il manque de souplesse au niveau de la purge des sauvegardes.
Vous connaissez sûrement Amazon S3, mais Amazon Glacier est plus récent et moins connu. Ce sont deux services AWS (Amazon Web Services), l’offre de Cloud Computing d’Amazon.
Amazon S3 peut être vu comme un espace de stockage de fichiers de taille illimitée à haute disponibilité. Les données sont disponibles en temps réel. On paye suivant la quantité de données stockée, pour un coût assez faible (pour donner un ordre d’idée, stocker 500 GO de données dans le datacenter de Londres coûte environ 12$ par mois), auquel s’ajoutent des frais suivant le nombre d’échanges et la quantité de données échangées. Un très grand nombre de services stockent leurs fichiers sur Amazon S3 pour ne plus avoir à s’embarrasser de la problématique du stockage.
Amazon Glacier est lui aussi un espace de stockage de fichiers illimité. Sauf que contrairement à S3, il a été conçu spécifiquement pour les stockages à très longue durée, qui n’ont pas forcément besoin d’être lus en temps réel. Le coût est extrêmement faible (compter 2,25$ par mois pour stocker 500 GO de données à Londres), mais en contrepartie la récupération de données peut prendre entre quelques minutes et 12 heures (suivant le tarif de récupération choisi).
Mon souhait était de pouvoir fonctionner (pour mes serveurs personnels) de la manière suivante :
- Sauvegarder tous les jours certains répertoires et certaines bases MySQL.
- Écrire ces sauvegardes sur le disque local, mais les copier aussi sur Amazon S3 et sur Amazon Glacier.
- Garder les sauvegardes sur le disque local pendant 3 jours avant de les effacer, pour que les versions les plus “fraîches” soient accessibles immédiatement en cas de problème.
- Attendre 2 semaines avant d’effacer les archives stockées sur Amazon S3, pour permettre une récupération relativement facile de données assez récentes, sans pour autant payer le stockage de données périmées.
- Garder sans limite de temps les archives stockées sur Amazon Glacier, pour avoir une trace de toutes les versions de mes fichiers.
Ça a l’air simple, vu comme ça, mais je n’ai pas trouvé d’outil me permettant de le faire simplement.
Et pour compliquer un peu les choses, mes besoins professionnels vont plus loin :
- Sauvegarder toutes les heures certains répertoires et certaines bases MySQL.
- Écrire ces sauvegardes en local, ainsi que sur Amazon S3 et Amazon Glacier.
- Garder toutes les sauvegardes (donc 24 sauvegardes par jour) en local pendant 3 jours ; puis n’en garder qu’une sur six (donc 4 sauvegardes par jour) pendant 4 jours ; puis une par jour pendant une semaine.
- Garder toutes les sauvegardes sur Amazon S3 pendant 2 semaines ; puis une sur quatre (6 sauvegardes par jour) pendant 2 semaines ; puis une par jour pendant un mois.
- Stocker les archives sur Amazon Glacier sans limite de temps.
Donc là il faut être capable de faire une sauvegarde toutes les heures, mais aussi gérer les purges (en local et sur Amazon S3) de manière très fine.
J’ai donc pris la décision de créer mon propre script de sauvegarde et d’archivage. Les habitués de ce blog se souviennent que j’ai écrit récemment un article sur l’utilisation de mysqldump, fournissant même un script de sauvegarde de bases MySQL qui allait jusqu’à copier les sauvegardes sur Amazon S3. Je suis juste passé à l’échelle supérieure.
Pour un maximum de portabilité, j’ai développé le programme en shell Bash. C’est le shell le plus courant sur les systèmes Unix/Linux. Ainsi, pas besoin d’interpréteur spécifique (ce qui serait le cas si je l’avais développé en PHP) et pas besoin de compilation (ce qui aurait été nécessaire si je l’avais codé en C).
Pour être le plus ergonomique possible − dans la mesure de ce qu’il est possible de faire en ligne de commande − j’ai pris le temps de faire deux choses :
- La configuration est interactive. La génération du fichier de configuration se fait en répondant à des questions (dont une majorité proposant des réponses par défaut) et non pas en remplissant à la main un fichier vide. Et le script ajoute automatiquement (enfin, si vous le souhaitez uniquement) Arkiv en Crontab pour qu’il soit exécuté automatiquement à la fréquence que vous souhaitez.
- J’utilise les capacités ANSI des terminaux pour faire un peu de mise-en-page des textes, avec de la couleur, des textes en gras ou en vidéo-inverse. Que ce soit pour la génération du fichier de configuration ou pour les logs d’exécution, cela facilite grandement la compréhension.
Et pour le nom du projet, j’ai choisi un mot qui veut dire “archive” dans plusieurs langues (notamment scandinaves ; un peu comme Skriv, qui veut dire “écrire” dans ces mêmes langues).
Comment installer Arkiv
La directive est assez simple, et expliquée sur la page GitHub du projet.
Pour commencer, il faut cloner le repository :
# git clone https://github.com/Amaury/Arkviv
Si vous souhaitez archiver sur Amazon S3 et Amazon Glacier : Avant de lancer le programme de configuration, il faut créer un “bucket” Amazon S3 et un “vault” Amazon Glacier (dans le même datacenter), puis créer un utilisateur IAM et lui donner les droits en lecture-écriture sur ce bucket et ce vault.
Ensuite on lance la configuration :
# cd Arkiv; ./arkiv config
Voici une copie d’écran d’un exemple d’installation :
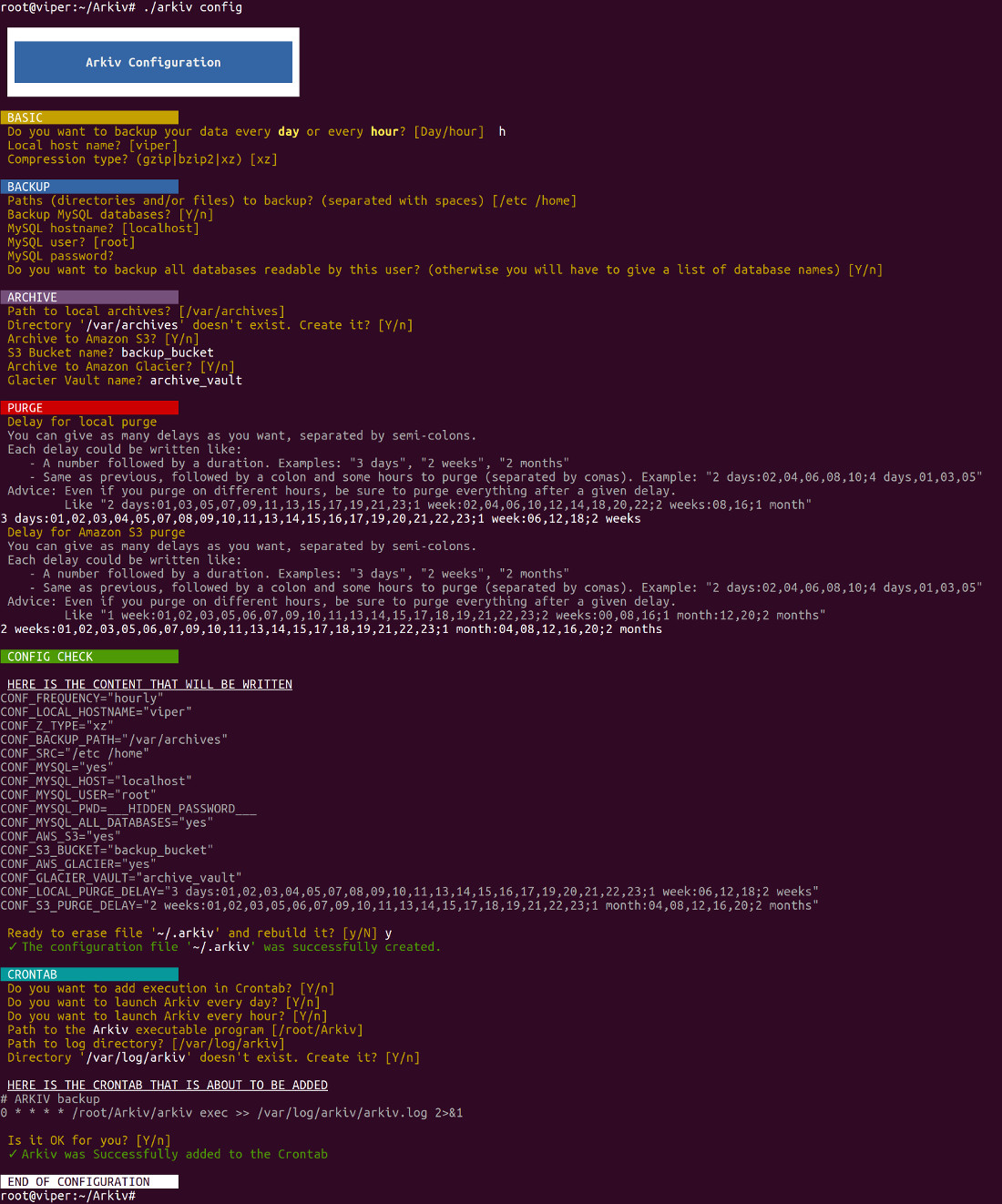
(Dans cet exemple, vous pouvez voir que les sauvegardes sont faites toutes les heures, archivées sur Amazon S3 et Amazon Glacier, et que les purges sont configurées assez finement.)
Il est possible de faire en sorte que les sauvegardes ne se fassent pas tous les jours et toutes les heures, mais de choisir une fréquence à la carte. Et comme il est possible d’utiliser plusieurs fichiers de configuration différents (en fournissant leurs chemins en paramètre), il est possible de mettre en place des politiques de sauvegarde assez complexes, pour coller au plus près des besoins.
À la fin de ce processus, le fichier de configuration est créé, et le programme a été ajouté en Crontab pour s’exécuter automatiquement.
À l’exécution
Lorsque le programme s’exécute, il passe par plusieurs étapes :
- Démarrage
- Arkiv est lancé par la Crontab.
- Il crée un dossier sur le disque local, qui accueillera les fichiers sauvegardés.
- Sauvegarde
- Tous les chemins listés dans la configuration sont compressés et le résultat est enregistré dans le dossier dédié.
- Si la sauvegarde MySQL est activée, les bases de données sont dumpées et sauvegardées dans le même dossier.
- Des checksums sont calculés pour tous les fichiers sauvegardés.
- Archivage
- Si l’archivage sur Amazon Glacier a été activé, tous les fichiers de sauvegarde y sont copiés. Pour chacun d’eux, un fichier JSON est créé, contenant la réponse renvoyée par Amazon. Ces fichiers contiennent les identifiants nécessaires à la récupération des fichiers.
- Si l’archivage sur Amazon S3 a été activé, le dossier et tout ce qu’il contient (fichiers de sauvegarde, fichier de checksum, fichiers JSON d’Amazon Glacier) y sont copiés.
- Purge
- Effacement sur le disque local des fichiers de sauvegarde qui ont atteint l’âge défini.
- Si l’archivage sur Amazon S3 a été activé, les fichiers de sauvegarde qui ont atteint l’âge défini sont effacés. Les fichiers de checksum et les fichiers JSON d’Amazon Glacier ne sont pas effacés, afin de permettre la récupération des fichiers archivés sur Amazon Glacier et d’en vérifier l’intégrité.
Sauf en cas de problème, l’exécution du programme se déroule de manière silencieuse.
Voici un exemple de ce que vous pourrez trouver dans le fichier de log :
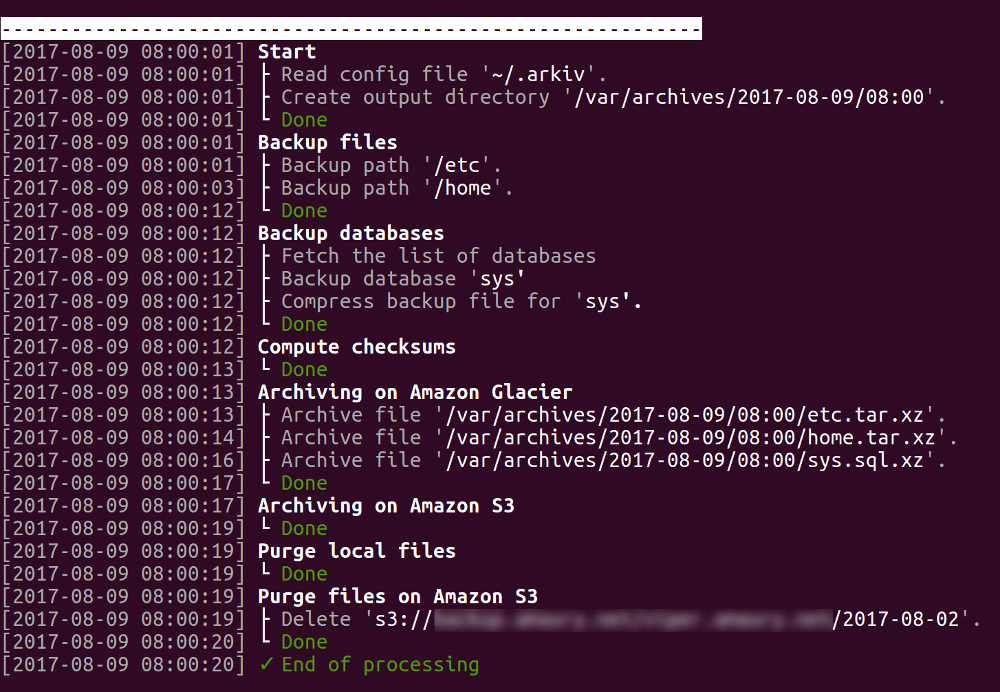
Vous pouvez voir que la « mise-en page » est là pour rendre les logs faciles à lire. Les éventuelles alertes et erreurs sont mises en avant grâce à de la couleur et des pictos.
Améliorations futures
Comme toujours, j’ai développé ce logiciel pour répondre à mes besoins, et je le rends accessible à tous sous licence libre parce qu’il pourra rendre des services à d’autres personnes que moi.
Je n’ai pas envie d’en étendre les fonctionnalités. L’archivage par FTP ou SCP, ou sur des plates-formes Cloud autres que celle d’Amazon, pourrait être pratique pour certains, mais cela complexifierait beaucoup le code. Arkiv ne se destine pas à être un outil obèse capable de tout gérer ; je préfère qu’il reste un outil avec des fonctionnalités réduites, mais qu’il adresse les bonnes fonctionnalités, et qu’il les accomplisse le mieux possible.
Donc on verra.
En attendant, n’hésitez pas à le tester et à me faire des retours. Si vous trouvez des bugs, vous pouvez utiliser la buglist fournie par GitHub.
Edit du 13 août : J’ai ajouté une fonctionnalité supplémentaire, l’encryption des fichiers (algorithme AES 256 bits par OpenSSL). Ça peut être utile pour les plus paranoïaques 😉
Edit du 29 août : J’ai ajouté le support des sauvegardes binaires de bases de données (utilisant l’outil xtrabackup), en global ou incrémental. Ainsi que l’écriture des logs dans syslog.
1 commentaire pour “Arkiv : Sauvegarde de fichiers et bases MySQL + archivage sur Amazon S3 et Amazon Glacier”